
Beyond the hype: Building a multi-agent system for E2E test generation
Eric Ventor
Software Engineer II
Edge, Advanced Technologies Group
Santa Monica, CA
At Metropolis, we’ve experienced explosive growth, scaling from 0 to 20,000 employees in just 7 years. This rapid expansion demands that engineering continuously stabilize and test the Metropolis platform as we scale to thousands of real estate partners and tens of millions of members. This scaling challenge became acutely visible in the monitoring of our in-house devices.
The rapid growth made the monitoring of Metropolis edge devices unwieldy. To address this, we created Edge UI, an observability app built to monitor our in-house designed and manufactured devices. Edge UI started as a small prototype and has grown into a pivotal part of our production workflows, used by our tech ops and operational teams.
Despite Edge UI growing into production workflows, it was still a prototype, degradation and partial outages of the internal tool were common. This was disrupting key operational workflows and increasing time to customer support. Following remediations, it was clear that most of the faults could have been prevented via improved test coverage. Therefore, we believed the most efficient path to take Edge UI from prototype to a fully productionized system was to increase our code coverage. To quickly productionize Edge UI, we invested in Claude Code subagents to automate the process of writing E2E tests for the existing ~100k line codebase. We theorized this bet could be valuable as Claude Code would not only speed up writing tests for existing code, but also generate tests for future features as well.
Agent architecture
We began by breaking down the core E2E test writing process into a three stage agentic workflow:
1. Test Identification: Determining which tests should be written (i.e., identifying areas with a lack of coverage)
2. Test Generation: Writing the tests themselves
3. Test Review: Reviewing the tests for effectiveness
To understand agent architecture, we must understand Claude Code’s implementation of agents and subagents. Claude Code uses a primary agent, this agent is the receiver and runner of the prompts inputted into the command line interface. The primary agent has access to a suite of tools to interact with your machine and the internet. It’s also capable of spinning up standalone Claude Code instances known as subagents. The key differentiator of a subagent is that it runs in its own process with its own context window, separate from the primary Claude Code agent. Our design leverages this by assigning each step of the process to a separate subagent, ensuring each one operates with a distinct, focused context. The structure of this agentic workflow is illustrated below.
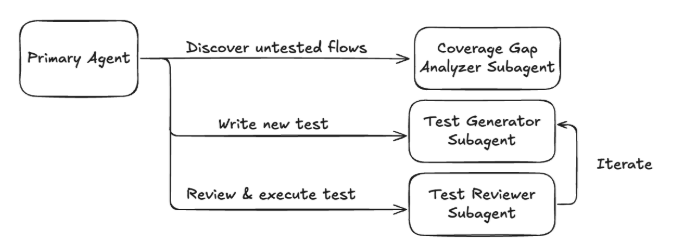
It’s important to note that (at the time of writing) subagents cannot spawn other subagents. Therefore, the primary Claude Code agent acts as the Orchestrator over all subagents. The Orchestrator manages the flow: it receives the output from one subagent, determines the next logical step, and passes the relevant context to the next subagent.
The results: agentic workflow success, lessons learned
Our goal was to quickly productionize Edge UI, a ~100k line codebase, through increased code coverage. To minimize time, we bet on an agentic workflow to automate both the identification of missing tests and the test creation itself. How’d it go?
The good
With standard back and forth prompting, we as humans must review every step of the output. With this approach, we are part of the feedback loop, and therefore the bottleneck. In order to reduce the amount of human touchpoints we aimed to automate the entire test writing process, including the review/iteration cycles. We leveraged unattended feedback mechanisms like compilers, linters, and test runners, which automate basic quality checks. However, to fully automate the complex review and iteration cycles required for writing quality tests, we introduced a specialized Test Reviewer Subagent.
The Test Reviewer Subagent was tuned to critique the output of the Test Generator Subagent. The Test Reviewer’s prompt included both general testing best practices and specific requirements for Metropolis’ internal patterns and testing standards. We found that using this dedicated Test Reviewer Subagent produced significantly higher quality tests than simply adding those same best practices and requirements to the Test Generator Subagent’s prompt. This design achieved a fully automated feedback loop of review, critique, and iteration on the generated tests, significantly reducing the number of manual back and forth cycles required from the human reviewer.
The bad
The initial E2E test generation agentic workflow was generic, focusing on widely applicable testing and framework guidelines, with hopes that it could be reused for other similar existing and future codebases. As we ran this workflow and aimed to improve the results, we learned providing team and codebase specific context was a large driver of quality improvement. Each iteration signaled necessary prompt modifications to further flesh out codebase specific context and expectations.
While continued iteration did improve the agentic workflow’s outputs, this improvement was a paradoxical negative for two reasons:
1. A human engineer was required to improve the agentic workflow for our specific codebase, requiring significant time investment.
2. It confirmed that codebase/domain specialized subagents with extensive context of our unique codebase and team expectations are superior to generic "QA Expert"-esque subagents.
Our experience proved that the tuning process is not “one and done.” The ideal would have been to engineer a single agentic workflow, and have the capability to deploy to other parts of the Metropolis organization. Most codebases are unique and require extensive, ongoing prompt engineering to achieve quality results.
The ugly
While we did successfully add some working E2E tests to Edge UI, we ultimately spent more time writing and improving the subagents than it would have taken a human engineer to write the tests directly. The work of iterating on the subagents’ prompts is still ongoing, with every run revealing endless necessary tweaks for Claude Code to output truly maintainable code.
Parallelization of test creation is not currently feasible. In theory, if our subagents generated quality tests, we could spin up n Claude Code instances and cover the entire codebase in minutes. In reality, the generated tests are suboptimal and consistently require human feedback within the iteration cycle.
Despite extensive prompt engineering efforts, the generated tests were suboptimal due to several key issues:
Over Testing: Generating excessive code to test trivial edge cases.
Poor Locator Strategy: Ineffective use of Playwright locators, leading to brittle tests.
Ignoring Basic Requirements: Failing to follow simple instructions, such as writing single responsibility tests or reducing unnecessary comments.
UI Flow Complexity: Struggling with slightly complex UI interactions, such as dynamic dropdowns.
Tight Coupling: Writing tests that are tightly coupled to volatile UI elements, resulting in high maintenance overhead.
Test Overlap: Often the same functionality would be tested in several test suites, ignoring instructions to prevent duplication.
Failing Tests: Occasionally, after several agentic review cycles, the primary agent would give up and cheerfully submit the tests as a final output despite them clearly failing.
Conclusion
Our journey with Claude Code subagents to accelerate E2E test coverage for Edge UI was a critical experiment in automating our engineering workflow. We successfully validated the agentic model, proving that an automated feedback loop using a specialized reviewer subagent for critique and iteration is not just feasible, but crucial for enforcing quality and standards adherence at scale. This automation allows humans to step out of a bottleneck, and is a clear structural win.
However, the cost of this validation was non-trivialundeniable, and the initial ROI was negative. The ugly truth is we spent significantly more time writing and iterating on the subagents’ prompts than a human engineer would have spent writing the tests. We discovered that quality automation is anything but "one and done." Subagents are not a set-it-and-forget-it feature; they are bespoke software that requires constant, deep-dive tuning into our codebase, team patterns, and organizational standards. The suboptimal quality of the generated tests confirms that parallelization is currently a pipe dream. The notion of spinning up n subagents to cover the codebase in minutes crashes hard against the reality that every generated test requires human oversight and feedback.
For now, making Claude Code an effective and trustworthy E2E test engineer is incomplete. We have built a powerful, but immature, new machine that requires continuous human calibration to produce maintainable code. The experiment continues, but the core takeaway is clear: AI cannot yet be trusted to fully automate essential parts of development workflows. While we are not yet at the autonomous future we envision, our commitment to staying ahead of the curve remains absolute. Our drive for innovation and real world experiments with advanced technologies will continue.
If tackling these kinds of complex, unsolved problems at scale sounds like your kind of engineering challenge, check out our careers page.